
Hosted as a Data Challenge Workshop as part of ACM MM 2017
Overview
We propose the 1st large-scale automatic kinship recognition challenge. This will be done using our Families In the Wild (FIW) image dataset [1] to support the data challenge workshop. The challenge will support 2 tasks, each addressing different real-world problems by well-defined data splits and evaluation protocols. These tasks are (1) Kinship Verification and (2) Family Classification. Participants will be allowed to participate in one or all tasks, as submissions and results will be handled separately. Tasks are defined by appropriate protocols (i.e., evaluation metrics), each of which have been benchmarked using conventional methods. A challenge page will be added to the FIW website, making all the information and resources easily accessible. Additionally, source code to reproduce benchmarks will be provided to demonstrate the end-to-end evaluation.
Task Evaluations
To address different real-world uses of automatic kinship recognition we benchmarked two tasks:
- Kinship Verification
- Family Classification
Kinship Verification

|
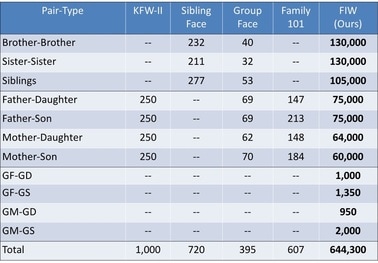
Table 1: Pair counts for FIW and related datasets.
|
Kinship verification aims to determine whether a pair of facial images are blood relatives of a certain type (e.g., parent-child). This is a classical Boolean problem with system responses being either KIN or NON-KIN (i.e., related or unrelated, respectfully). Thus, this task tackles the one-to-one view of automatic kinship recognition.
Data Splits
We use all face pairs for each of the 11 categories. The total number of pairs (T in Figure 1) is the count for each category. Of these, half are true pairs and half are negative. Data is split into five folds of equal size. No family overlap between folds.
Evaluation Settings & Metrics
As conventional face verification, we offer 3 modes, which are listed & described as follows:
For all modes, the underlying metric used is accuracy, which is averaged across the five folds. Also, ROC curves will also be used when reporting results.
- Unsupervised: No labels given, i.e., no prior knowledge about kinship or subject IDs.
- Image-restricted: Kin/ non-kin labels given for training set, with no family overlap between training and test sets.
- Image-unrestricted: Kinship labels & IDs given– allows mining for additional negative pairs.
For all modes, the underlying metric used is accuracy, which is averaged across the five folds. Also, ROC curves will also be used when reporting results.
Family Classification
Data Splits
Again, we use 5-fold cross validation with no family overlap between folds. Each fold contains roughly 1,500 images—meaning 4x this (i.e., about 6,000 faces) are used for testing and about 1,500 faces used for testing each split. Hence, each split used a different fold to test, while training on other 4 folds.
Evaluation Settings & Metrics
The results for this multi-class problem will be reported as top 1% error ratings and visualized as confusion matrices.
We attached the Pilot Results based on the experimental setting above in the next page.
We attached the Pilot Results based on the experimental setting above in the next page.
Kinship verification tests were run on previously tested pairs such as siblings, mother – daughter, father – son, etc. along with four newly introduced multi generational pairs between grandparents and grandchildren in the FIW database. With the Fine-Tuned CNN model, we saw an average of a 4% increase in accuracy from the VGG-Face model. The benchmark tests were completed by randomly selecting an equal number of positive and negative pairs for each family, then computing cosine similarity for each pair.
Because of families' large intra-class variations, family classification has proven to be more challenging than both search and retrieval, and kinship verification. Moreover, faces with variations in pose, lighting, expression, etc. increase the task's difficulty. Our fine-tuned model's benchmarks had an average of about 13.3%, only 1% higher than the VGG model, as stated on the results page. The Families in the Wild database contributes a sufficient amount of data to run tests and improve these benchmark scores. APPLICATIONS? To participate in this challenge, click here for more information (WILL LINK TO EVALUATION PLAN).
